4. Critique
We compiled and tested a version of the SQLite database engine that was released in the year 2002 (i.e. more than 20 years ago). We encountered several issues during this exercise. Developing a fix for these issues provided valuable insight into the factors that contribute to intelligibility and maintainability of a program code and its documentation. These insights are presented as a critique below.
4.1 Change is the only constant in a software.
Everything changes and nothing stands still. Heraclitus (a Greek philosopher)
A software tool lives and thrives in an ecosystem created by hardware (e.g. CPU, memory, etc.), operating system and dependent software libraries. This ecosystem is continually changing in order to address the requirements of the changing world. Therefore, change is the only constant also in the life of a software. It is wiser to accept and embrace the fact that changes to a software will be necessary as it moves forward in time.
A class of updates in a software that will prevent normal operation of
other software tools or services that depends on the software is
called a breaking change. While nobody wants to commit such
breaking changes, they are sometimes essential. The
Issue
2.1 has revealed that it is important to have flags or
markers that caution the users of such breaking changes at the
point of usage. The GCC compiler developers have wisely chosen
to include a varargs.h file in all GCC compiler
distributions -- since 2004 -- which produces an informative
error message when the compiler attempts to use the unsupported
varargs.h header file. Such wise decisions has and
will help many software maintainers in the future.
File: /usr/lib/gcc/.../include/varargs.h
#ifndef _VARARGS_H
#define _VARARGS_H
#error "GCC no longer implements <varargs.h>."
#error "Revise your code to use <stdarg.h>."
#endif
Posting critical information at the point of usage is an important construct for introducing a breaking change. In the case of compilers, this involves showing an informative error message when a user tries to access an unsupported feature. Further details about a breaking change can also be disseminated through other forms of communication like mailing list, software release document, etc. For example, the GCC compiler release document contains a clear and concise notice about this breaking change.
GCC no longer ships<varargs.h>. Use<stdarg.h>instead. GCC 3.4 Release Series
The developers of the Tcl library could not provide information about
a breaking change at the point of usage. To find a fix for
Issue
3.1, a maintainer has to explore the software
documentation. A more intelligible compiler error message suggesting a
corrective action would have been more useful. For example, a software
trying to access the result field of the Tcl_Interp
data structure should be informed with an error message that this
feature is no longer available without defining the macro
USE_INTERP_RESULT. The GCC compiler permits, for example,
the deprecated attribute for a function to show a warning if
an unsupported function gets used. However, such a feature is not
available for data member access and is the reason, most likely, why
such informative warnings were not generated when the result
field of the Tcl_Interp data structure was accessed.
4.2 To depend or not to depend, is a profound question that the wise can answer.
The SQLite developers chose to rely on a non-standard feature
(i.e. vararg.h) provided by the compilers of their
time (i.e. year
2002). The Issue
2.1 revealed that dependence on non-standard features makes
the software vulnerable to changes in ecosystem thereby
increasing maintenance costs.
Issue 3.1 revealed another fact about software dependencies; if software A depends on a software library B then it implies that A has accepted that its fate is tied with the fate of B. The SQLite software uses the TCL library to implement its test suite. One can understand the benefit of this dependence; it allows the SQLite developers to easily write tests in the Tcl language which is more concise, clear and easier to maintain. The cost of such dependence is often overshadowed by the benefits. This dependency required the SQLite software to act whenever the Tcl library introduces any breaking changes.
"To depend or not to depend is the question my dear developers", would have asked Shakespeare if he were reflecting on the pros and cons of software dependencies. All dependencies have a cost and understanding the cost is the first step in taking a wise decision on whether to depend on a third party library or to develop your own functionality. A wise developer will look at the benefits and costs of a software dependency with certain degree of impartiality in order to truly evaluate the impact of such dependencies.
4.3 Unitary (or atomic) revisions to a version control system are more useful.
Software developers often use a Version Control System (VCS) to keep a historical record of changes (or, revisions) being made to a software. Such historical record of revisions not only helps understand the growth of a software and its structure but also allows changes to be removed with surgical precision when the software behaves in undesirable ways. It is easier to understand and reason about a revision that introduces only one conceptual change (e.g. a feature, a bug fix, a new test case, etc.) in a software. Such revisions can be said to be unitary (or atomic) as they reflect a unit of change in the software.
The value of unitary revisions were realised while fixing the
Issue
2.2. The getline() identifier name conflict with the
standard library was fixed as
a single
revision in the version control history of the SQLite. This
revision contained relevant keywords (e.g. getline) in the
revision log message that made it easier to locate. Such a unitary
revision was not available
for Issue
2.1 whose fix was more difficult to develop as the fix required
manually selecting code updates from one of
the future
revisions. Therefore, unitary (or atomic) revisions with a
revision log containing all the relevant keywords are useful. When
deciding about the keywords relevant for a revision, it helps to think
about a learner who is allowed to search the revision log history
using only one or two keywords.
4.4 Global Identifier Names Should be both Unique and Intelligible
The developers of sqlite-2002 came up with the getline()
method name well before the method was defined in the standard library
through the local_getline() which not
only avoided conflict with the getline() method in the
standard library but also avoided any future conflicts with other
software. This was a wise decision because the updated method name has
survived more than 20 years of change in compilers and standard
libraries.
In some programming languages, like the C programming language, the
identifier names (e.g. function names, variable names, etc.) are
stored in either global or local scope. Names stored in the global
scope (e.g. function names such as getline()) are accessible
to all parts of the program and therefore have greater chance of
conflicting with other parts of the software (e.g. standard
library). Identifiers in the local scope (e.g. variable names defined
within a function) are only accessible in that local scope and
therefore has smaller chance of conflict with other identifiers
defined in that scope. Here is an example, taken from the SQLite code,
showing identifiers in both global and local scope.
File: sqlite/src/shell.c
static char *getline(char *zPrompt, FILE *in){
char *zLine;
int nLine;
...
}
In the above code snippet, the function name getline() is
stored in the global scope and therefore it can be invoked from any
part of the program including the local scope of any other
function. On the other hand, the variable zPrompt,
in, zLine, nLine are
stored in the local scope of the getline() function and
therefore these variables are only accessible from within
the getline() function.
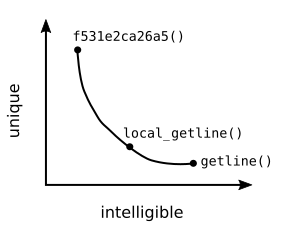
Programmers have to deal with the following two conflicting requirements when crafting the identifier names that have to live in the global scope.
- Uniqueness : The identifier names must to be unique so that it does not conflict with identifiers that are currently defined and the identifiers that will get defined in the future in other parts of the software (e.g. standard library, dependent libraries, etc.). So the challenge for the programmer is to think of an identifier name that cannot be possibly thought by anyone else.
- Intelligibility : The identifier names should be intelligible in order to convey the purpose of that identifier to the reader. The more informative an identifier name is, the more useful it is to the reader.
If one chooses a fairly unique name (e.g. f531e2ca26a5) then it is
unlikely that this identifier name will ever conflict with any other
identifiers. However, such identifier names will not be intelligible
to the readers as it does not convey any meaning. On the other hand,
one can chose a highly intelligible identifier name
(e.g. getline()) that fully conveys the purpose of the
method. However, such an intelligible name would also invite conflict
as it is highly likely that others will also want to use such an
intelligible name for a function that has a similar
purpose. Therefore, one has to chose an identifier name that lives in
the global scope by carefully balancing the uniqueness and
intelligibility requirements. The developers of SQLite chose such a
balance by adding the prefix local to the method name.
Many programming languages have introduced the concept of namespace to
compartmentalise global identifier names into buckets (or, namespace)
such that these identifiers can only be accessed using the name of the
bucket. For example, in the C++ programming language the
getline() method defined by the standard library would be
placed in the std namespace and be accessed using
std::getline() identifier name. The getline() function
defined by the SQLite database engine would be placed in the sqlite
namespace, for example, and would be accessed using
sqlite::getline() identifier name. One could argue that this
is similar to the practice of adding a prefix (or suffix) to an
identifier name in order to avoid conflicts. This is a valid
argument. However, a feature provided by the compiler makes the
concept of namespace more useful in reducing conflict and improving
intelligibility. Namespaces have a scope and if an identifier is used
within a namespace, then one can remove namespace name prefix from the
identifier name. The default compiler behaviour is to assume that all
identifier names without the namespace prefix correspond to the
current namespace. This feature helps to improve intelligibility while
maintaining uniqueness. However, the reader is required to be aware of
the current namespace in order to correctly resolve an identifier
name.
4.5 Tests build trust
Test suite of a software is commonly seen as a tool by the developers and for the developers because it is used by a developer to verify the functionality of a software. The software resurrection exercise has highlighted another role of a test suite; a test suite is also a valuable tool for building trust with the users.
Successful compilation of a 20 year old software (i.e. sqlite-2002) on a modern platform brought happiness and a sense of achievement during the software resurrection exercise. However, these feelings of achievement were quickly overshadowed by the realisation that the sqlite-2002 software may not be reliable on a modern platform. Successful compilation on a modern platform does not provide the assurances required to rely on this software for storing critical information like financial or medical data. The self contained test suite shipped with this software was able to automatically test various parts of the database engine and report the test results as shown below.
bigrow-1.0... Ok
bigrow-1.1... Ok
bigrow-1.2... Ok
...
btree-1.2... Ok
btree-1.3... Ok
btree-1.4... Ok
...
These concise messages from the test suite containing 5096 test cases confirmed that the freshly compiled SQLite database engine was performing as expected even after significant changes in hardware and software that could not have been foreseen 20 years ago. The test suite was designed by the developers of SQLite who can be reasonably expected to correctly quantify the desired behaviour of their software. Therefore, the results from this test suite is more convincing and is able to build trust with its users which would not have been possible otherwise.
4.6 Tests define the expected behaviour of a software.
The sqlite-2002 documentation states that this version of sqlite, "implements a large subset of SQL92" standard and allows "atomic commit and rollback protect data integrity". It is possible to prepare some SQL query statements based on the SQL92 standard and prepare some SQL tables to test atomic commits. However, will these be sufficient to confirm that the software is truly behaving in the way it was designed to operate during its release in the year 2002? Furthermore, how can one possibly know what was the desired behaviour of sqlite-2002 as envisaged by its developers 20 years ago?
It is possible to formally specify the expected behaviour of a software. One can also write a detailed documentation describing the expected behaviour. While none of these are available for sqlite-2002, the historical software release does include a set of self contained and automated tests which allow one to quickly and easily verify the functionality of the software on a new platform. These tests not only verify functionality but also act as a concrete specification of the expected behaviour of the software as envisaged by its developers 20 years ago. For example, one can understand the expected behaviour of the database storage engine of sqlite-2002 by reviewing all the test cases defined in the \texttt{test/btree.test} source file. Therefore, tests are not only useful for verifying the functionality of a software but also are valuable for concretely specifying the expected behaviour of the software.
4.7 Who tests the Test?
But who will guard the guardians themselves? Juvenal (Satire VI)
An automated and self contained test suite is a program code that has been designed to test a software. The test suite invokes various features of the software with a set of test inputs and compares it against a set of corresponding test outputs. If the test suite has a complex logic and involves substantial amount of program code then the test suite merits a testing process for itself to ensure that the test code does not have any flaws. This leads to a recursive testing dependency in which a tests suites is developed to test another test suite. Such a never ending scenario can only be avoided by a test suite that is so simple that it does not demand a test for itself. A simple test suite has minimal code and has minimal chances of failure. Only such a simple test suite is capable of assuring that a failed test case points to a failure in the software being tested and does not correspond to a flaw in the test code itself.
The test cases (e.g. btree-1.1) in sqlite-2002 are defined
using the Tcl programming language (e.g. test/btree.test). The
core sqlite database engine is defined using the C programming
language (e.g. src/btree.c). A test driver layer contains a
set of functions (e.g. btree_open defined in
src/test{1,2,3}.c) that allows the Tcl based test
specifications to access functionality of the core sqlite database
engine. Figure below illustrates the control
and data flow for the test case btree-1.1 which verifies the
ability of the sqlite engine to create a new database and represent it
using the btree data structure stored in a disk file.
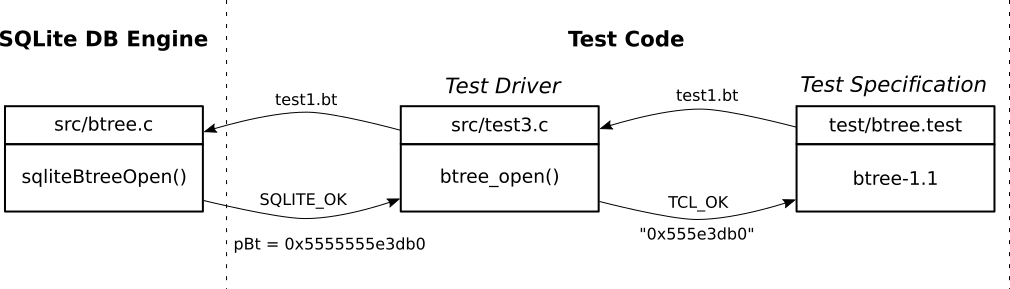
The sqlite-2002 tests failed to run on a modern 64 bit platform
because the test driver layer assumed that memory addresses were 32
bits long. Such an assumption broke most of the test code because the
driver layer wrongly translated 64 bit pointer addresses (e.g.
0x5555555e3db0) to 32 bit pointer addresses (e.g.
0x555e3db0) by dropping the higher 32 bits of the
address portion. The test code did not operate properly and
therefore failed to properly test the software. The test
control and data flow shown in figure below must have its
merits and therefore was chosen by the sqlite-2002
developers. However, this failure forces one to rethink about
introducing any complexity in test suites and aim for tests
that are based on the most fundamental and stable features of
a compiler.
4.8 SQLite-2002 is an intelligible and maintainable software
The SQLite database engine that was released 20 years ago can
be compiled in a modern hardware and software platform. It also
delivers all the features included in the original software release as
evidenced by successful execution of the regression tests. The program
code and regression tests required corrective software maintenance in
order to address the changes in the hardware and software
libraries. These maintenance activities could be performed by a modern
day developer because the program code is well documented. A
README text file provides an inviting introduction to the
software. Every function definition in the source code includes a
clear and concise description of its purpose. The user defined data
types are intelligible because of their identifier names as well as
the comments accompanying them. The software's architecture and
purpose of its various components are also well documented in a set of
self contained and static and offline HTML files that are generated by
the autoconf's make doc command. These documents and
comments, written 20 years ago, communicates to a modern day developer
with remarkable effectiveness and clarity. The sqlite-2002 software is
therefore an intelligible and maintainable software that is equally
valuable for learning some of the software engineering principles.